Anthropic's new Claude 4 AI models can reason over many steps
- May 22, 2025
- Category:
During its inaugural developer conference Thursday, Anthropic launched two new AI models that the startup claims are among the industry's best, at least in terms of how they score on popular benchmarks.
Claude Opus 4 and Claude Sonnet 4, part of Anthropic's new Claude 4 family of models, can analyze large datasets, execute long-horizon tasks, and take complex actions, according to the company. Both models were tuned to perform well on programming tasks, Anthropic says, making them well-suited for writing and editing code.
Both paying users and users of the company's free chatbot apps will get access to Sonnet 4 but only paying users will get access to Opus 4. For Anthropic's API, via Amazon's Bedrock platform and Google's Vertex AI, Opus 4 will be priced at $15/$75 per million tokens (input/output) and Sonnet 4 at $3/$15 per million tokens (input/output).
Tokens are the raw bits of data that AI models work with. A million tokens is equivalent to about 750,000 words — roughly 163,000 words longer than "War and Peace."
Anthropic's Claude 4 models arrive as the company looks to substantially grow revenue. Reportedly , the outfit, founded by ex-OpenAI researchers, aims to notch $12 billion in earnings in 2027, up from a projected $2.2 billion this year. Anthropic recently closed a $2.5 billion credit facility and raised billions of dollars from Amazon and other investors in anticipation of the rising costs associated with developing frontier models.
Rivals haven't made it easy to maintain pole position in the AI race. While Anthropic launched a new flagship AI model earlier this year, Claude Sonnet 3.7, alongside an agentic coding tool called Claude Code, competitors — including OpenAI and Google — have raced to outdo the company with powerful models and dev tooling of their own.
Anthropic is playing for keeps with Claude 4.
The more capable of the two models introduced today, Opus 4, can maintain "focused effort" across many steps in a workflow, Anthropic says. Meanwhile, Sonnet 4 — designed as a "drop-in replacement" for Sonnet 3.7 — improves in coding and math compared to Anthropic's previous models and more precisely follows instructions, according to the company.
The Claude 4 family is also less likely than Sonnet 3.7 to engage in "reward hacking," claims Anthropic. Reward hacking, also known as specification gaming, is a behavior where models take shortcuts and loopholes to complete tasks.
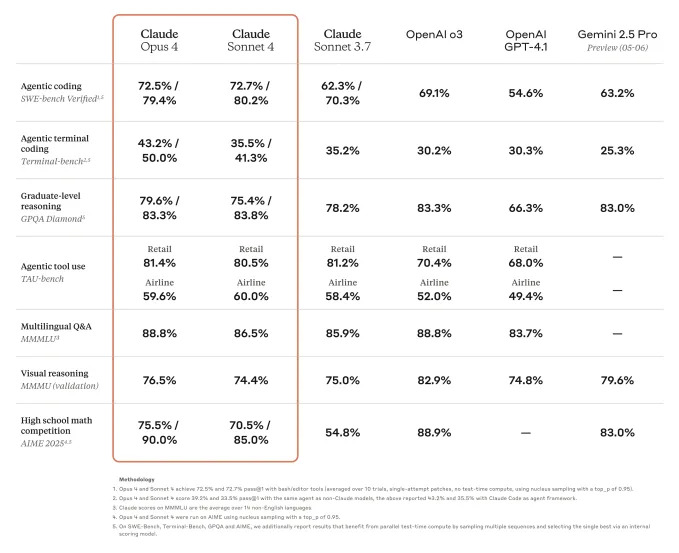
To be clear, these improvements haven't yielded the world's best models by every benchmark. For example, while Opus 4 beats Google's Gemini 2.5 Pro and OpenAI's o3 and GPT-4.1 on SWE-bench Verified, which is designed to evaluate a model's coding abilities, it can't surpass o3 on the multimodal evaluation MMMU or GPQA Diamond, a set of PhD-level biology-, physics-, and chemistry-related questions.